
Had my alerting system yell at me about high CPU load on my Splunk Free VM;
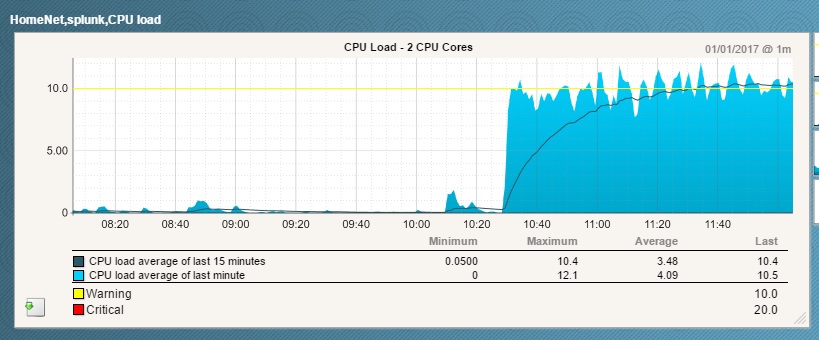
A bit of examination revealed that it was indeed at abnormally high load average (around 10), although there didn’t appear to be anything wrong. Then a quick look at dmesg dropped the penny;
Jan 1 10:29:59 splunk kernel: Clock: inserting leap second 23:59:60 UTC
Err. The high CPU load average started at 10:30am, right when the leap second was added.
A restart of all the services resolved the issue. Load average is back down to its normal levels.